CSC3170 数据库系统 Database System
Part 1 简介 Introduction
结构化和非结构化的文本信息 Structured and Unstructured Textual Information
一个数据库管理系统(Database Management System, DBMS)是一个复杂的软件系统,其任务是帮助管理大量复杂的结构化信息。
结构化信息通常由离散的单元(实体 Entities)组成。
相同类型的实体会有预设的组织方案:
- 相同数量的性质 Attributes
- 每个性质都有预设的格式
非结构化的信息通常指没有固定格式、没有区分信息的数据,一般为普通的文本。
数据库系统 Database System
包含信息的数据集合叫做数据库。
其应用非常广泛,包括但不限于:
- 销售:顾客、产品、购买
- 会计:支付、发票
- 人力资源:应聘者信息、销售人员、税收
- 管理层
- 银行和金融
- 大学
数据库的目的是什么?主要是为了高效地存储、维护和查找大量数据,而且要保证不出现安全问题。
数据视图 View of Data
数据库系统是一些相互关联的数据以及一组使得用户可以访问和修改这些数据的程序的集合,其主要目的是给用户提供数据的抽象视图。
数据模型 Data Model
数据模型是描述数据、数据联系、数据语义以及一致性约束的概念工具的集合。其可以被划分为四类:
- 关系模型(Relational Model):利用表的集合来表示数据和数据间的联系,是最广泛的数据模型。
- 实体-联系模型(Entity-relationship Model):主要用作数据库设计。
- 半结构化数据模型(Semi-structured Data Model):允许数据定义中某些相同类型的数据项含有不同的属性集,例如 JSON, XML。
- 基于对象的数据模型(Objecte-based Data Model):面向对象的程序设计,例如 Java, C++, C#。
下面这个图是最常见的关系模型例子:
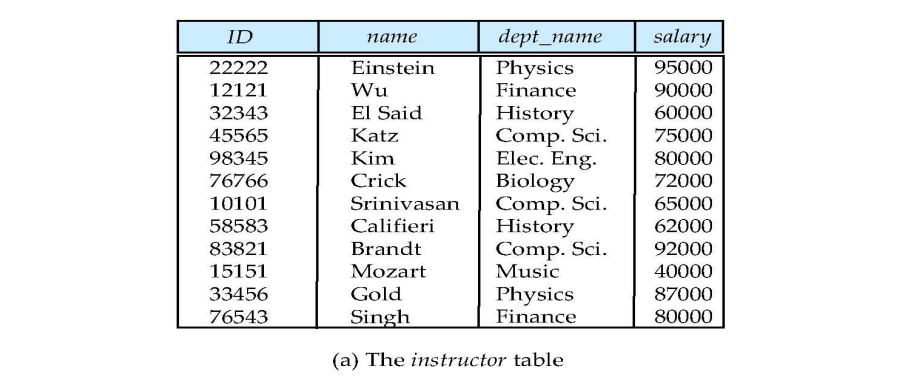
数据抽象 Data Abstraction
一个可用的系统必须要能高效地检索数据,系统开发人员通过如下几个层次的数据抽象来对用户屏蔽复杂性,以简化交互:
- 物理层(Physical Level):最低层次的抽象,描述数据实际上是怎样储存的。
- 逻辑层(Logical Level):描述数据库中存什么数据以及这些数据间存在什么联系。
- 视图层(View Level):只描述整个数据库的某个部分。
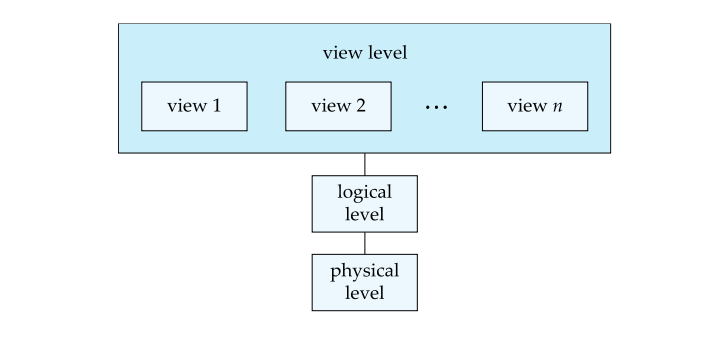
实例和模式 Instances and Schemas
随着时间的推移,信息会被插入或删除,数据库也就发生了改变。特定时刻存储在数据库中的信息的集合称作数据库的一个实例 Instance,而数据库的总体设计称作数据库模式 Schema。
数据库有几种模式:
- 物理模式(Physical Schema),在物理层描述数据库的设计。
- 逻辑模式(Logical Schema),在逻辑层描述数据库的设计。
- 子模式(Subschema),描述数据库的不同视图。
物理数据隔离 Physical Data Independence:在不改变逻辑模式的情况下改变物理模式的能力。
数据库语言 Database Language
数据定义语言 Data Definition Language (DDL)
定义数据库模式的专用标记,例如:

DDL 编译器会生成一系列表格模板,存在数字典 Data Dictionary 里。
数据字典包含元数据 Metadata:
- 数据库模式
- 完整性约束 Integrity Constraints
- Primary Key
- 授权
- 验证谁可以访问
数据操纵语言 Data Manipulation Language (DML)
可以使得用户访问或操纵,那些按照某种适当的数据模型组织起来的数据,通常也叫做查询语言。基本上有两种类型:
- 过程化的 DML(Procedural DML),要求用户指定需要什么数据以及如何获得这些数据
- 声明式的 DML(Declarative DML),只要求用户指定需要什么数据,不必指明如何获得
声明式的 DML 通常也被称为非过程化的 DML。
结构化的查询语言 Structured Query Language (SQL)
SQL 是非过程化的,一个查询包含输入一个或多个表格,返回一个表格。例子:
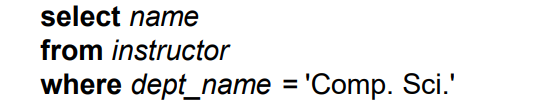
数据库设计 Database Design
设计数据库通常结构的流程:
- 逻辑设计 Logical Design:决定数据库模式。数据库设计要求我们能找到一个“好的”关系模式。
- 物理设计 Physical Design:决定数据库的物理层。
数据库组成 Database Components
一个数据库系统可以被划分成以下几个功能性模块:
- 储存管理器 Storage Manager
- 查询处理器 Query Processor
储存管理器 Storage Manager
储存管理器是数据库系统中负责在数据库中储存的低层数据与应用程序以及向系统提交的查询之间提供接口的部件。
储存管理器负责以下任务:
- 与操作系统文件管理器交互
- 高效地储存、检索和更新数据
储存管理器实现了以下几种数据结构:
- 数据文件(Data File):储存数据库它本身
- 数据字典(Data Dictionary):储存数据库结构的元数据
- 索引(Index):能提供对数据项的快速访问
查询处理器 Query Processor
查询处理器组件包括:
- DDL 解释器(DDL Interpreter):解释 DDL 语句并将这些定义记录在数据字典中
- DML 编译器(DML Compiler):将查询语言中的 DML 语句翻译为包括一系列查询执行引擎能理解的低级指令的执行方案
- 一个查询通常可以被翻译成给出相同结果的多个候选执行计划中的任何一个。DML 编译器还进行查询优化(Query Optimization),就是从几个候选执行计划中选择代价最小的那个执行计划。
- 查询执行引擎(Query Evaluation Engine):它执行由 DML 编译器产生的低级指令。
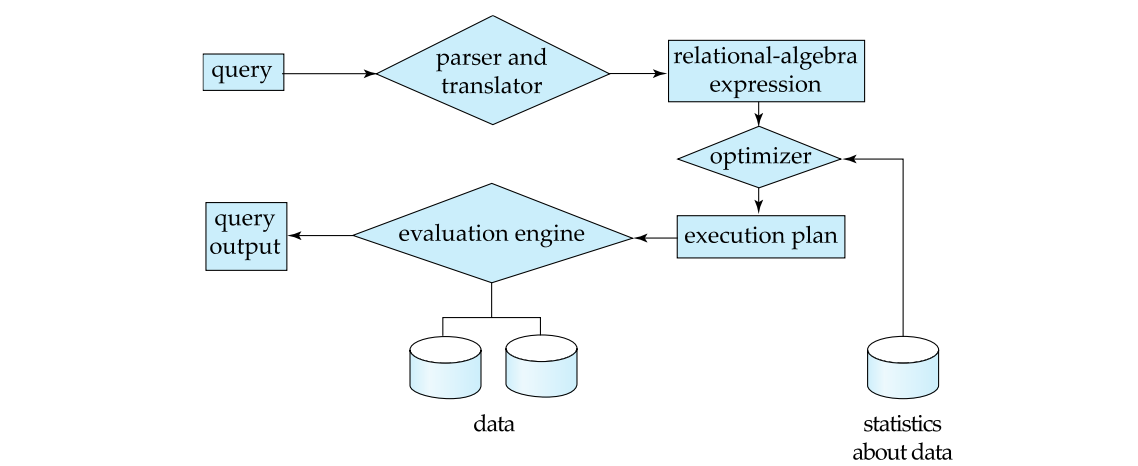
事务管理 Transaction Management
事务 Transaction是数据库应用中完成单一逻辑功能的操作集合。
数据库架构 Database Architecture
- 中心化的数据库
- 一些核心,共享内存
- 客户端-服务器
- 一个服务器机器执行基于多个客户端的工作
- 平行数据库
- 多核,共享内存
- 共享硬盘
- 什么都不共享
- 分布式数据库
- 地理上的分布
- 模式 / 数据异质性
数据库用户和管理员 Database Users and Administrator
数据库用户:
- 普通(初学者=)用户
- 应用程序员
- 复杂(老练)用户
数据库管理员:
- 模式定义
- 存储结构及存取方法定义
- 模式及物理组织的修改
- 数据访问授权
- 日常维护
Part 2 关系模型介绍 Introduction to Relational Model
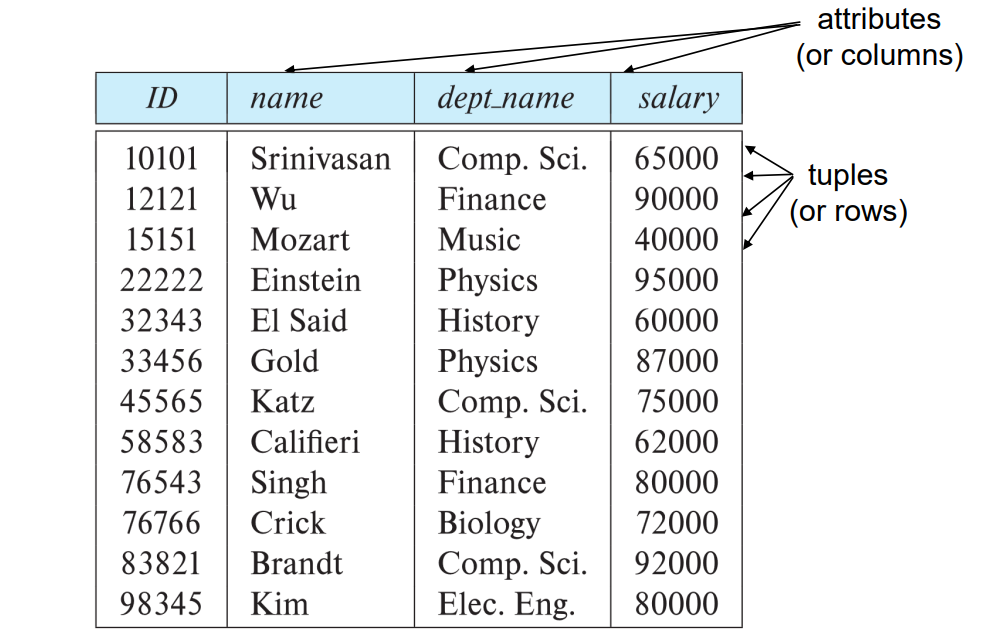
关系数据库由表 Table的集合构成,每张表被赋予一个唯一的名称。
一个关系表的例子:
关系的数学定义 Mathematical Definition of Relation
笛卡尔积 Cartesian Product
考虑两个任意集合 $A$ 和 $B$,包括所有有序对 $(a,b), a \in A, b \in B$ 的集合叫做 $A$ 和 $B$ 的笛卡尔积。 $$ A \times B = {(a,b):a \in A, b \in B} $$ 如果 $A=B$,我们通常将 $A \times A$ 写成 $A^2$。
- e.g. 如果$A = \mathbb{R}$,那么 $\mathbb{R}^2$ 就是二维笛卡尔平面。
记集合 $A$ 的基数 Cartesian 为 $|A|$,则有 $$ |A \times B| = |A| \times |B| $$
从 $A$ 到 $B$ 的一个二元关系 Binary Relation $R$,就是 $A \times B$ 的一个子集,即 $R \subseteq A \times B$
一般来说,定义在集合 $D_1,D_2,\cdots,D_n$ 上的 $n$ 元关系 n-ary Relaion $R$ 是笛卡尔积 $$ D_1 \times D_2 \times \cdots D_n $$ 的一个子集,即 $$ R \subseteq \prod_{k=1}^n D_k $$ 其中,$D_1,D_2,\cdots,D_n$ 通常被称为域 Domain。
并且该笛卡尔积的基数为 $$ \left| \prod_{k=1}^n D_k \right| = \prod_{k=1}^n \left| D_k \right| $$ 也就是说,笛卡尔积的元素个数等于各个集合基数的乘积。
如果某个特定元组 tuple 出现在关系 $R$ 中,就表示该元组所表达的信息在当前是真实且有效的信息。
举个例子,假设
- $D_1=$ 学号
- $D_2=$ 学院
- $D_3=$ 生源城市 如果 $$ (114514, \text{CS}, \text{Shenzhen}) \in R $$ 表示学号为 $114514$ 的学生属于 CS 学院,并且来自深圳。但是 $$ (114515, \text{CE}, \text{Guangzhou}) \notin R $$ 表示“学号为 $114515$ 的学生属于 CE 且来自广州”这一说法不成立。
关系模式和实例 Relation Schema and Instance
$A_1, A_2, \cdots, A_n$ 被称为属性 attributes。
$R(A_1, A_2, \cdots, A_n)$ 被称为关系模式 relation schema,有时也被称为关系方案 relation scheme,它由关系名和属性列表组成,这些属性对应表中的列 columns。
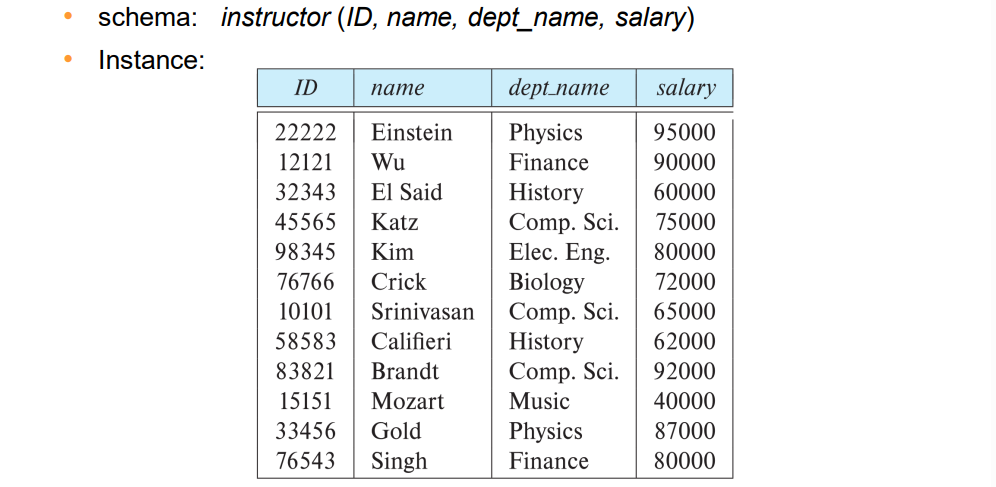
- e.g. instructor(ID, name, dept_name, salary)
定义在关系模式 $R$ 上的关系实例 relation instance(也被称为关系状态 relation state)记为 $$ r(R) $$ 它由实际的数据值组成
- 一个关系当前的取值通常通过一张表 table 来表示
关系 $r$ 中的一个元素 $t$ 被称为元组 tuple,在表中用一行 row 来表示。
模式描述的是逻辑结构,而实例时某一时刻数据的快照。
例如下图
属性 Attributes
每个属性允许取值的集合称为该属性的域 domain。
属性值通常要求是原子性的 atomic,即不可再分的。
特殊值 null 被认为时每个域中搞的一个成员,表示该值未知。
null 值会使许多数据库操作的定义变得更加复杂。
键 Keys
设 $K \subseteq R$,如果属性集合 $K$ 的取值足以认证唯一标识关系 $R$ 的一个元组 tuple,则称 $K$ 为 $R$ 的一个超键 superkey。
- e.g. ${\text{ID}}$ 和 ${\text{ID}, \text{name}}$ 都是关系 instructor 的超键。
如果一个超键 $K$ 是最小的 minimal,则称之为候选键 candidate key。
- e.g. ${\text{ID}}$ 是 instructor 的一个候选键。
在所有候选键中,会选择一个作为主键 primary key。
外键 foreign key 约束:一个关系中的某个值必须出现在另一个关系中。
- 引用关系 referencing relation
- 被引用关系 referenced relation
关系代数 Relational Algebra
关系代数由一组运算组成,这些运算接受一个或两个关系作为输入,并生成一个新的关系作为它们的结果。
六个基础运算符:
- 选择 select:$\sigma$
- 投影 project:$\Pi$
- 集合并 union / 交 intersection:$\cup$
- 集合差 set difference:$-$
- 笛卡尔积 Cartesian product:$\times$
- 更名 rename:$\rho$
选择运算 Select Operation
选择运算选出给定满足给定谓语的元组。
记号:$\sigma_p(r)$
其中,$p$ 被称作选择谓词 selection predicate。
- e.g. 选择满足在 Physics 部门的 instructor:
$$ \sigma_{\text{dept name="Physics"}}(\text{instructor}) $$
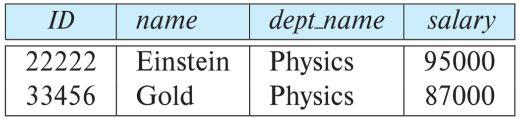
在选择运算中我们允许使用 $=,\not=,>,\geq,<,\leq$,也可以利用连接符号 $\land,\lor,\lnot$ 结合谓语。
- e.g. 选择满足在 Physics 部门且薪水高于 $90,000 的 instructor:
$$ \sigma_{\text{dept name="Physics" } \land \text{ salary > 90,000}}(\text{instructor}) $$
投影运算 Project Operation
投影运算是一种一元运算,返回它的参数关系,但滤掉了特定的属性。
记号:$\Pi_{A_1, A_2, A_3, \cdots, A_k} (r)$
其中 $A_1, A_2, A_3, \cdots, A_k$ 是属性名,$r$ 是关系名。
- e.g. 查询以下属性的 instructor
$$ \Pi_{\text{ID, name, salary}}(\text{instructor}) $$
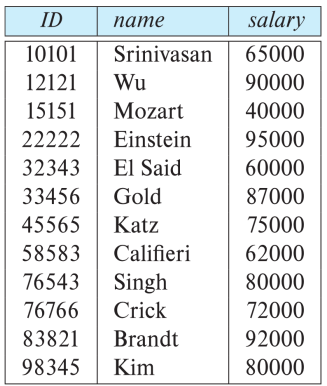
其实就是去掉了 dept_name。
关系运算的组合 Composition of Relational Operations
因为一个关系代数运算的结果也是关系,所以可以直接连接起来(就像函数括号),例如:
$$ \Pi_{\text{name}}(\sigma_{\text{dept name="Physics"}}(\text{instructor})) $$
笛卡尔积运算 Cartesian Product Operation
笛卡尔积运算用叉号 $\times$ 表示,允许我们结合来自任意两个关系的信息。其作用就是,假设现在有 $n$ 行的关系 $A$ 和 $m$ 行的关系 $B$,那么 $A \times B$ 就会得到一个 $n*m$ 的关系,$A$ 中的每一个关系都对应 $B$ 中的所有关系。
- e.g. instructor $\times$ teaches
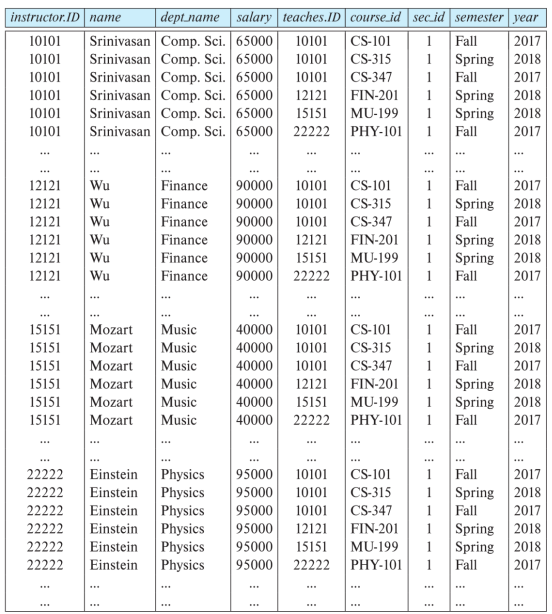
这里找不到原来两张表的电子版了,但大概就是能看出来是原来的一条左边的关系对应右边的所有关系,这样形成一个 $n*m$ 行的关系
连接运算 Join Operation
连接运算是我们能够选择与笛卡尔积合并到单个运算中。
考虑关系 $r(R)$ 和 $r(S)$,并令 $\theta$ 为 $R \cup S$ 模式的属性上的一个谓词。连接运算的定义是: $$ r \bowtie s = \sigma_\theta (r \times s) $$
- e.g. $\text{instructor} \bowtie_{\text{instructor.id = teaches.id}} \text{teaches} \\ = \sigma_{\text{instructor.id = teaches.id}}(\text{instructor} \times \text{teaches})$
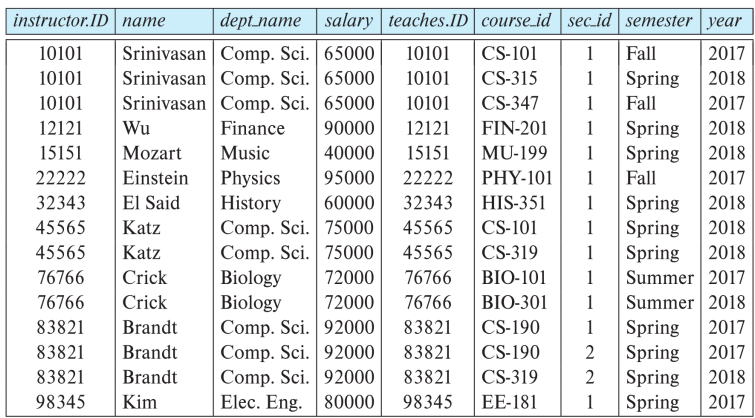
其实就是先做了笛卡尔积运算,再做一次选择运算。
集合运算 Set Operation
并运算 Union Operation
并运算使我们能够合并两个关系。
为了使并集运算有意义,必须要保证:
- 输入并运算的两个关系具有相同数量的属性,一个关系的属性数量被称为它的元数 Arity。
- 当属性有关联的类型时,对于每个 $i$,两个输入关系的第 $i$ 个属性的类型必须相同。
这样的关系被称为相容 Compatible 关系。
记号:$r \cup s$
交运算 Intersection Operation
交运算允许我们找到同时出现在两个输入关系中的元组。
与并集运算一样,我们要保证交是在相容关系之间进行运算的。
记号:$r \cap s$
集差运算 Set-Difference Operation
集差运算能使我们找到在一个关系中但不在另一个关系中的元组。
与并集运算一样,我们要保证集差是在相容关系之间进行运算的。
记号:$r - s$
因为教授的 PPT 上并没有很好的例子图示,在这里就不给出了,而且这三个集合运算也很好理解。
赋值运算 Assignment Operation
有时候通过将一个关系代数表达式中的一部分赋值给临时的关系变量,可以方便地编写该表达式,赋值运算用 $\leftarrow$ 表示,其工作方式类似于程序语言中的赋值。
- e.g. 找到所有在 Physics 和 Music 部门的 instructor $$ \begin{align*} &\text{Physics} \leftarrow \sigma_{dept name="Physics"}(instructor) \\ &\text{Music} \leftarrow \sigma_{dept name="Music"}(instructor) \ &\text{Physics} \cup \text{Music} \end{align*} $$
更名运算 Rename Operation
关系表达式的结果并没有可以用来指代它们的名称,更名运算使我们能够做到这一点。
记号:$\rho_x(E)$
能返回以 $x$ 命名的表达式 $E$ 的结果。
Part 3 实体-联系模型 The Entity-Relationship Model
实体-联系数据模型(E-R 数据模型)被开发来方便数据库的设计,它是通过允许定义代表数据库全局逻辑结构的企业模式 Enterprise Schema 来做到的。
E-R 数据模型包含下面三个基本概念:
- 实体集 Entity Sets
- 关系集 Relationship Sets
- 属性 Attributes
实体集 Entity Sets
实体 Entity 是现实世界中可以区分于所有其它对象的一个“事物”或“对象”。
- e.g. 特定的人,公司,活动
实体集 Entity Set 是共享相同性质或属性的、具有相同类型的实体的集合。
- e.g. 所有人的集合,公司集合,产品
实体通过一组属性 Attributes 来表示,属性是实体集中每个成员所拥有的描述性性质。
- e.g. $\text{instructor}=(\text{ID, name, salary})$
属性的子集构成了一个实体集的主键 Primary Key,即它可以唯一认定集合的元素。
实体集在 ER 图里的表示:
关系集 Relationship Sets
联系 Relationship 是多个实体间的相互关联,关系集 Relationship Set 是相同类型联系的集合。
关系集的数学定义: $$ {(e_1, e_2, \cdots, e_n):e_1 \in E_1, e_2 \in E2, \cdots, e_n \in E_n } $$ 其中,$(e_1, e_2, \cdots, e_n)$ 是个联系。
例如,我们定义一个关系集 advisor 表示 student 和 instructor 之间的关联,然后我们就可以在实体之间连线。
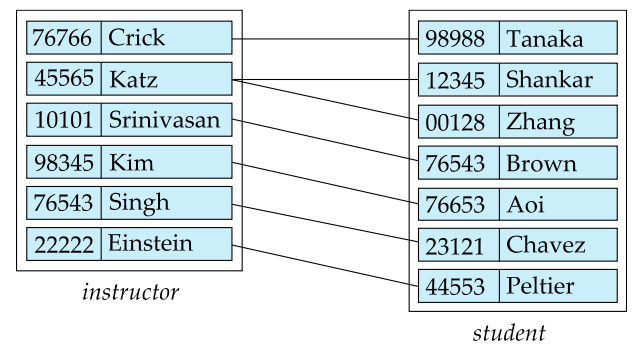
关系集在 ER 图里的表示:
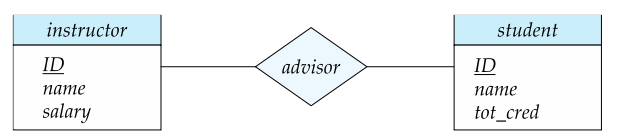
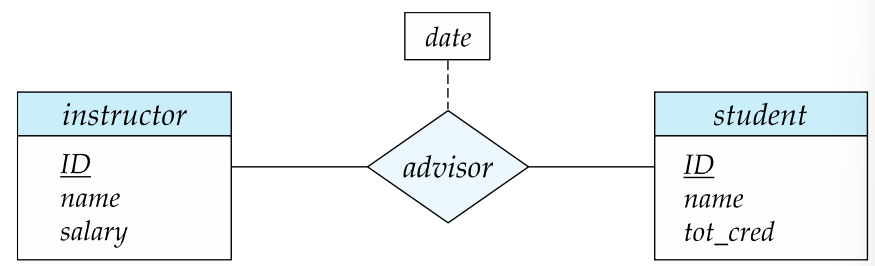
联系也可以具有被称作描述性属性 Descriptive Attribute 的属性。
例如下图,每个联系具有一个 date,表示 student 和 instructor 建立 advisor 联系的时间。
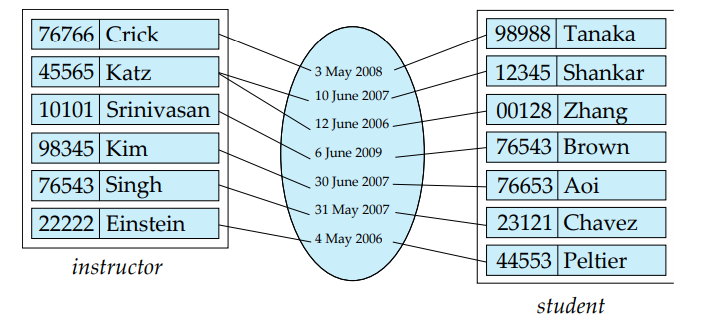
带有属性的关系集在 ER 图里的表示:
实体集的关系不需要是独特的,实体在联系中扮演的功能被称为实体的角色 Role。
下图中,course_id 和 prereq_id 被称作角色。
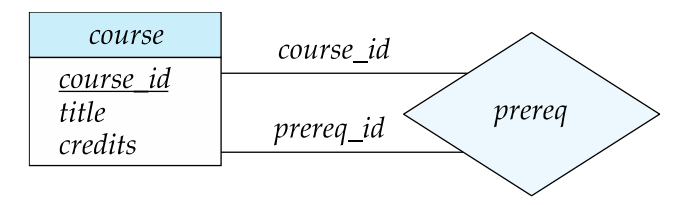
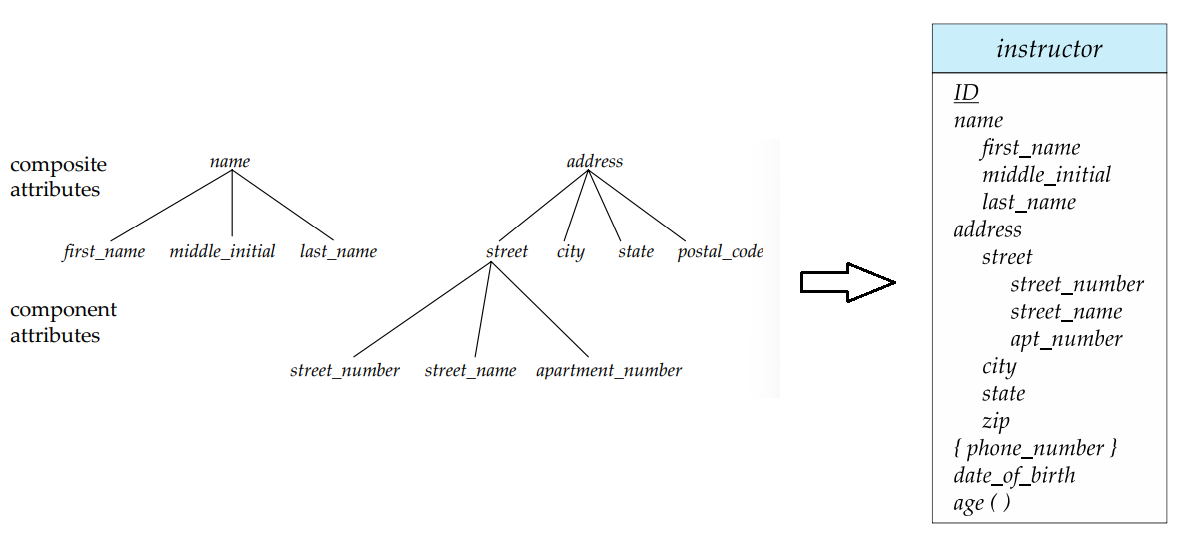
复杂属性 Complex Attributes
映射基数 Mapping Cardinality
映射基数 Mapping Cardinality 或基数比率表示一个实体能通过一个关系集关联的另一些实体的数量,多用于描述而二元关系集。
对于一个二元关系集来说,映射基数必然是以下情况之一:
- 一对一 One-to-one
- 一对多 One-to-Many
- 多对一 Many-to-one
- 多对多 Many-to-many
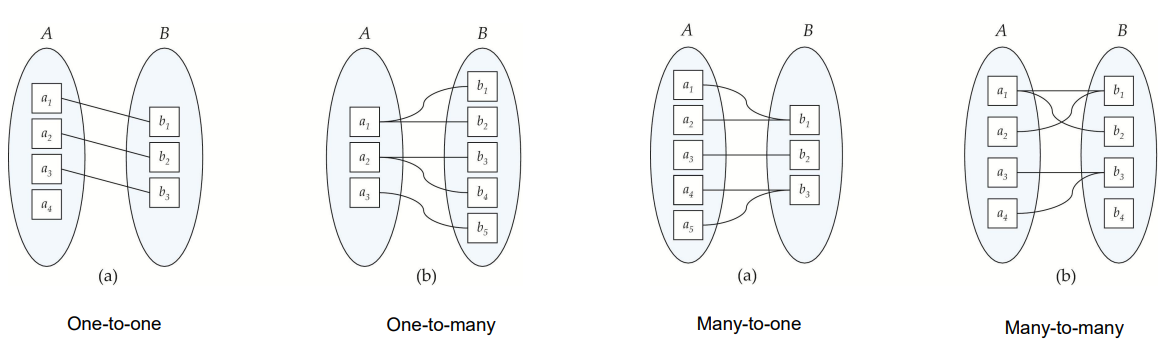
在 ER 图中,我们用单箭头直线($\rightarrow$)来表示“一”,用无箭头之间($-$)来表示“多”。下图从左上到右下分别是一对一、一对多、多对一、多对多。
其中,一对一在这里的意思就是,一位导师最多可以指导一名学生,一名学生最多只能有一位导师;一对多在这里的意思就是,一位导师可以知道多名学生,但一名学生最多只能有一位导师;其余同理。
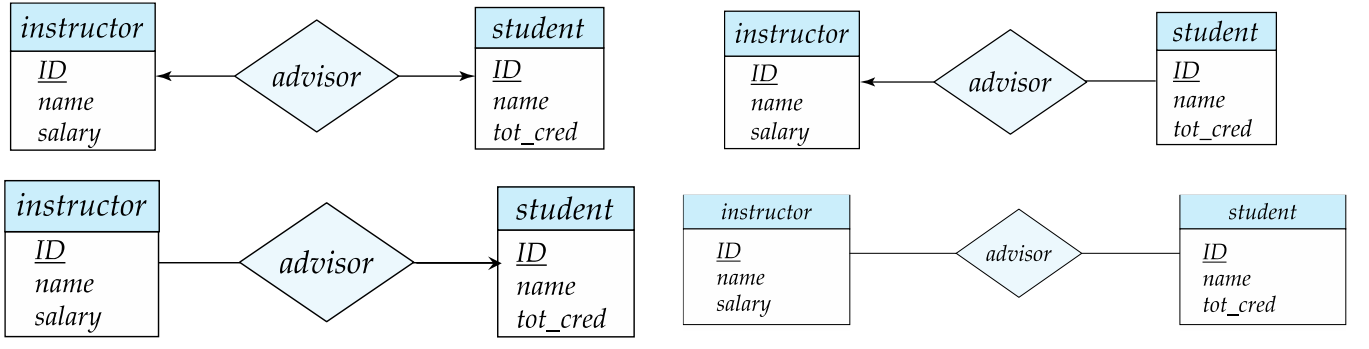
全部和部分参与 Total and Partial Participation
如果实体集 $E$ 中的每个实体都必须参与到关系集 $R$ 的至少一个联系中,那么实体集 $E$ 在关系集 $R$ 中的参与就被称为是全部的 Total,否则就被称为是部分的 Partial。
全部参与用双直线表示。
例如下图:
student 在 advisor 关系集中的参与是全部的,即每个学生都至少有一位导师。instructor 在 advisor 关系集中的参与是部分的,即一位导师不是必须要指导学生。
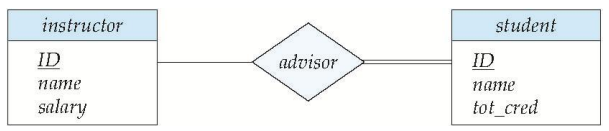
更复杂的约束 More Complex Constraints
线段上可以有一个关联的最小和最大基数,用 $l..h$ 的形式表示,其中 * 表没有限制。示例如下图:
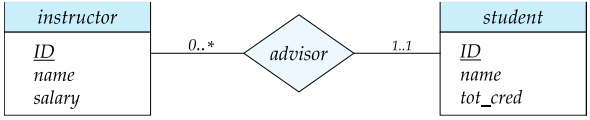
导师可以指导 $0$ 个或多个学生;一个学生至少有一个导师,无上限。
Generated by ChatGPT
下面从 Primary Key 开始,按你给出的课程结构一直讲到 Multivalued Dependency 与 Fourth Normal Form。我尽量保持 定义式、考试导向、少换行、逻辑紧凑的形式。
Part 3(后半)Primary Key, Weak Entity, Schema Representation
Primary Key(主键)
定义:在关系模式 (R) 中,若属性集合 (K) 满足以下两个条件,则称 (K) 为 Primary Key: (1) 唯一性(uniqueness):任意两个不同元组在属性 (K) 上的取值不同。 (2) 最小性(minimality):(K) 的任何真子集都不满足唯一性。
换句话说,Primary Key 是从 Candidate Keys(候选键) 中选出的一个作为主要标识符的键。Candidate Key 是所有满足唯一性与最小性的属性集合,而 Superkey 是任何能唯一标识元组的属性集合(不要求最小性)。因此关系为: Superkey ⊇ Candidate Key ⊇ Primary Key。
Prime Attribute 指属于某个 Candidate Key 的属性,Non-prime Attribute 指不属于任何 Candidate Key 的属性。
在关系模型中通常还涉及 Foreign Key:若关系 (R) 中属性集合 (F) 的值必须出现在另一关系 (S) 的 Primary Key 中,则称 (F) 为引用 (S) 的 Foreign Key。
Weak Entity Sets(弱实体集)
弱实体是 没有完整主键的实体集,其存在依赖于另一个实体集(称为 identifying entity)。弱实体的标识需要两个部分: (1) Partial Key(部分键):弱实体内部可区分对象的属性集合。 (2) Owner Entity 的 Primary Key。
因此弱实体的主键为: Owner Primary Key ∪ Partial Key。
例如:Employee(emp_id) 与 Dependent(name, age)。Dependent 无法仅通过 name 唯一标识,需要 (emp_id, name) 才能唯一确定一个 dependent。
在 ER 图中弱实体通常用 双矩形表示,identifying relationship 用 双菱形表示,且弱实体必须 total participation 于 identifying relationship。
Representing Schema(ER 到关系模式)
将 ER 模型转换为关系模式通常遵循以下规则: (1) 实体集 → 关系模式:实体的属性成为关系的属性,实体的主键成为关系的 Primary Key。 (2) 弱实体 → 关系模式:加入 owner entity 的主键作为外键并与 partial key 组成复合主键。 (3) 1:N relationship:在 N 端关系中加入 1 端的主键作为 Foreign Key。 (4) M:N relationship:建立新的关系模式,其属性为两个实体主键的并集(再加上关系属性)。 (5) relationship attributes:作为新关系模式中的属性出现。
Part 4 Extended Entity-Relationship Features
EER(Extended ER)模型在普通 ER 的基础上增加了 更复杂的建模能力,核心包括 specialization、generalization 与 aggregation。
Specialization(特化) 指从一个高层实体集派生出多个子实体集,每个子实体集具有额外属性或语义。例如 Person → Student、Employee。子类自动继承父类属性。
Generalization(泛化) 是 specialization 的逆过程,将多个实体抽象为一个更一般的实体。例如 Car 与 Truck 可以泛化为 Vehicle。
在 EER 中还涉及两个重要约束: (1) Disjointness constraint:子类之间是否互斥。若 disjoint,则一个实体最多属于一个子类;若 overlapping,则可属于多个子类。 (2) Completeness constraint:是否 total specialization。若 total,则每个父类实体必须属于某个子类;若 partial,则可以不属于任何子类。
另一个扩展概念是 Aggregation,用于表示“关系之间的关系”。例如 Manager 管理 Works_on 关系(员工参与项目),此时需要把 Works_on 看作一个高层对象参与新的关系。
Part 5 Relational Database Design and Normalization
关系数据库设计的目标是 减少冗余并避免更新异常(update anomaly)。常见异常包括: Insertion anomaly:无法插入某些信息而不引入无关数据; Deletion anomaly:删除数据时丢失其他有用信息; Update anomaly:同一事实需在多处修改。
为解决这些问题,需要进行 Normalization(规范化),即通过分析 Functional Dependencies(函数依赖) 将关系分解为多个结构更合理的关系模式。规范化通常涉及一系列范式(Normal Forms),如 1NF、2NF、3NF、BCNF、4NF 等。数据库设计通常希望达到 BCNF 或至少 3NF,同时保持 lossless join 与 dependency preservation。
Lossless Join 指将关系分解为多个关系后,通过自然连接可以恢复原关系。 Dependency Preservation 指原有函数依赖可以在分解后的关系中被直接验证。
Part 6 Functional Dependency Theory
Functional Dependency(FD) 是规范化理论的核心。
定义:在关系模式 (R) 中,属性集合 (X) 到属性集合 (Y) 的函数依赖记为 (X → Y),若对任意两个元组 (t_1,t_2),只要 (t_1[X] = t_2[X]),则必有 (t_1[Y] = t_2[Y])。
Trivial FD:若 (Y ⊆ X),则 (X → Y) 为平凡函数依赖。
Attribute Closure:给定属性集 (X) 和函数依赖集合 (F),闭包 (X^+) 是在 (F) 下由 (X) 可推出的所有属性集合。计算闭包的算法为:初始化 (X^+=X),若存在 FD (A→B) 且 (A ⊆ X^+),则加入 (B) 到 (X^+),重复直到不再变化。
闭包用于: (1) 判断 Candidate Key(若 (X^+) 包含所有属性,则 (X) 为 superkey); (2) 判断 FD 是否由 (F) 推导。
Armstrong’s Axioms 提供了推导函数依赖的基本规则: Reflexivity:若 (Y ⊆ X),则 (X → Y)。 Augmentation:若 (X → Y),则 (XZ → YZ)。 Transitivity:若 (X → Y) 且 (Y → Z),则 (X → Z)。
从这三条可推导出 union、decomposition、pseudo-transitivity 等规则。
3NF 与 BCNF
BCNF(Boyce–Codd Normal Form)定义:若对所有非平凡 FD (X → Y),都有 (X) 为 superkey,则关系模式在 BCNF 中。
Third Normal Form(3NF)定义:若对每个 FD (X → Y),满足以下之一: (1) (X) 是 superkey; (2) (Y) 为 prime attribute; (3) 该 FD 为 trivial。
BCNF 比 3NF 更严格。BCNF 能消除更多冗余,但分解后可能不保持依赖,而 3NF 保证存在 dependency-preserving decomposition。
Part 7 Multivalued Dependency and Fourth Normal Form
Multivalued Dependency(MVD) 表示为 (X →→ Y)。其含义是:若两个元组在 (X) 上相同,则可以交换它们在 (Y) 上的值而仍属于该关系。直观上表示:对于同一 (X),(Y) 的取值集合与其他属性是独立的。
例如关系 Student(student, skill, language),若学生的技能与语言互不影响,则存在 student →→ skill student →→ language。
这种情况下数据会出现冗余组合,例如若某学生有两种 skill 和两种 language,则需要存储四条记录。
Fourth Normal Form(4NF)定义:若对于每个非平凡 MVD (X →→ Y),都有 (X) 为 superkey,则关系模式在 4NF 中。
当存在违反 4NF 的 MVD 时,需要将关系分解。例如将 Student(student, skill, language) 分解为 StudentSkill(student, skill) 与 StudentLanguage(student, language)。
这种分解既消除了冗余,又保持无损连接。
Generated by Gemini Pro
Final Exam:
- 判断题、单选题、填空题、大题
- multivalue/function depengden
- 4nf/bcnf
- lossless decompose
- indexing
- b tree
- cap theorem(no sql)
- H base
- recovery track(undo...)
Part 7 Multivalued Dependency and Fourth Normal Form
收到,这份 Part 7 讲的是多值依赖 (MVD) 和 第四范式 (4NF)。
这份 PPT 看起来全都是希腊字母 $\alpha, \beta, \gamma$,但其实核心就是在解决一个开发中极容易碰到的傻逼设计:把两个完全不相干的 一对多 (1-to-N) 关系,硬塞到了同一张表里 。
核心拿分点(必考大题:4NF 分解与证明)
如果你在卷子上看到形如 $A \rightarrow \rightarrow B$ 的符号(中间是两个箭头),这就是在考 MVD 和 4NF。大题一定会让你把一张烂表无损分解 (Lossless Decomposition) 成 4NF 。
1. 什么是 MVD ($\alpha \rightarrow \rightarrow \beta$)?
-
大白话: 属性 $\alpha$ 决定了一组 $\beta$ 的值,并且这组 $\beta$ 的值跟表里的其他属性完全没有关系 。
-
PPT 例子: 一个老师 (ID) 有多个小孩 (child_name),也有多个电话 (phone_number) 。小孩和电话互不干涉。如果全塞进一张表
inst_info(ID, child_name, phone_number),就会出现恐怖的笛卡尔积(数据冗余) 。为了保持数据合法,你必须把小孩和电话的所有组合都列出来 。
2. 什么是 4NF?
- 判断标准: 对于表里的每一个非平凡的 MVD ($\alpha \rightarrow \rightarrow \beta$),左边的 $\alpha$ 必须是超码 (Superkey)(也就是说 $\alpha$ 能唯一确定一行记录)。如果 $\alpha$ 不是超码,这张表就不满足 4NF 。
3. 💥 必背拆表公式(4NF Decomposition Algorithm): 当一张表 $R$ 违背了 4NF(存在 $\alpha \rightarrow \rightarrow \beta$,但 $\alpha$ 不是超码),直接套这个公式把它劈开 :
-
新表 1: 包含 MVD 的左右两边 $\rightarrow (\alpha, \beta)$
-
新表 2: 左边 $\alpha$ 保留,加上表里剩下的所有属性 $\rightarrow (R - \beta)$
-
实战推导(参考 PPT 第 17 页): 已知 $R=(A,B,C,G,H,I)$,依赖有 $A \rightarrow \rightarrow B$、$B \rightarrow \rightarrow HI$、$CG \rightarrow \rightarrow H$ 。
-
第一步: 拿 $A \rightarrow \rightarrow B$ 开刀(A 不是超码,违背 4NF)。拆成 $R_1 = (A, B)$ 和 $R_2 = (A, C, G, H, I)$ 。
-
第二步: 检查 $R_2$。里面有个 $CG \rightarrow \rightarrow H$(CG 不是 $R_2$ 的超码)。把 $R_2$ 拆成 $R_3 = (C, G, H)$ 和 $R_4 = (A, C, G, I)$ 。
-
第三步: 检查 $R_4$。利用传递性,既然 $A \rightarrow \rightarrow B$ 且 $B \rightarrow \rightarrow HI$,所以推导出 $A \rightarrow \rightarrow HI$,在这个 $R_4$ 表里就是 $A \rightarrow \rightarrow I$ 。把 $R_4$ 拆成 $R_5 = (A, I)$ 和 $R_6 = (A, C, G)$ 。
4. 如何证明是无损分解 (Lossless Decomposition)?
-
判定条件: 拆出来的两个表 $R_1$ 和 $R_2$,它们的交集,必须能多值决定 (multi-determines) 其中任何一张表 。
-
公式: $R_1 \cap R_2 \rightarrow \rightarrow R_1$ 或者 $R_1 \cap R_2 \rightarrow \rightarrow R_2$ 必须成立 。
概念防坑指南(专门对付选择题 / 判断题)
- 平凡多值依赖 (Trivial MVD): 什么时候 MVD 是“平凡的”(也就是废话)?满足以下两点之一即可:
-
右边本来就是左边的子集 ($\beta \subseteq \alpha$) 。
-
这张表里只有这两个属性 ($\alpha \cup \beta = R$) 。
- FD vs MVD: 所有的函数依赖 (FD) 都是多值依赖 (MVD) 的特例。即如果 $\alpha \rightarrow \beta$ 成立,那么 $\alpha \rightarrow \rightarrow \beta$ 一定成立 。FD 要求只能有 1 个值(等值生成),MVD 允许有一组值(元组生成)。
- 4NF 和 BCNF 的关系: 只要一张表是 4NF,它绝对是 BCNF(4NF 条件更苛刻)。
- 反范式化 (Denormalization): 为什么有时候我们要故意违反范式,把数据塞在一张表里?纯粹是为了查询性能 (faster lookup),避免耗时的 JOIN 操作 。
Part 8 - 9 SQL
Skip
Part 10 NoSQL and Big Data Storage Systems
核心拿分点 1:CAP 定理(必考选择 / 简答题)
这个你在做后端架构时肯定听过,分布式系统的“不可能三角” 。教授非常喜欢考这三个字母的含义以及为什么只能“三选二” 。
-
C (Consistency 一致性): 强一致性。你往节点 A 写入了数据,立刻去节点 B 读,读到的必须是最新写入的数据 。
-
A (Availability 可用性): 只要系统没死绝,用户的请求就必须有响应(哪怕给的是旧数据),不能报错或无响应 。
-
P (Partition Tolerance 分区容错性): 哪怕节点之间的网线被挖断了(网络裂脑,分成了几个孤岛),系统依然要能继续运行 。
-
考场防坑逻辑: 在现实世界的分布式系统中,P(网络故障)是必然会发生的 。一旦发生网络分区,你要么为了保证 C(一致性)而拒绝服务(此时失去 A),要么为了保证 A(可用性)而返回各节点的旧数据(此时失去 C)。所以现实中往往采用最终一致性 (Eventual Consistency) 来保 A 和 P 。
核心拿分点 2:HBase 数据模型(极其容易考填空 / 对比题)
教授上一份透题里明确提到了 H base,这绝对是重头戏。你要抛弃 MySQL 那种固定的二维表思维。HBase 底层就是一个巨大的、稀疏的、多维的、嵌套的 Map (字典) 。
-
五维坐标定位: 在 HBase 里,要找到一个具体的数据(Cell),必须通过以下 5 个维度的 Key 来定位,请死记硬背这个 5-tuple 公式:
(Table, RowKey, ColumnFamily, ColumnQualifier, Timestamp)。如果查询时不写 Timestamp,默认返回最新版本的数据 。 -
Column Family (列族) vs Column Qualifier (列限定符):
- 列族 (Column Family): 建表的时候就必须定死,物理存储上同一个列族的数据存在一起 。
- 列限定符 (Column Qualifier): 极其灵活,插入数据时动态生成(比如你突然想存个微信号,直接插就行,不需要 ALTER TABLE) 。
- 它们组合成具体的列:
Family:Qualifier(例如Name:Fname或Details:Job) 。
-
Row Key (行键): HBase 里的数据是严格按照 Row Key 的字典序 (lexicographically) 排列的 。
核心拿分点 3:MapReduce 执行流程(大题预警)
如果教授要考 Big Data 的计算题,90% 的概率是让你手写或推导 MapReduce 的 Word Count(词频统计)流程 。只要记住这三个核心阶段的输入输出长什么样就行。
假设输入文件有两行:Deer Bear River 和 Car Car River 。
- Map 阶段(各干各的): Worker 读取自己分到的数据,把每一个单词拆出来,不管三七二十一,直接输出一个带数字 1 的键值对 。
- 输出:
(Deer, 1),(Bear, 1),(River, 1),(Car, 1),(Car, 1),(River, 1)。
- 输出:
- Shuffle 阶段(系统自动完成的洗牌): 把所有 Map 输出的键值对,按照 Key (单词) 进行分组和合并,把相同 Key 的 Value 塞进一个列表里发给对应的 Reduce 机器 。
- 系统输出:
(Car, [1, 1]),(River, [1, 1]),(Deer, [1]),(Bear, [1])。
- 系统输出:
- Reduce 阶段(汇总收网): 针对每一个 Key,把它的 Value 列表里的数字全加起来 。
- 最终输出:
(Car, 2),(River, 2),(Deer, 1),(Bear, 1)。
- 最终输出:
核心概念(选择题扫一眼就行)
-
Sharding (分片): 把一个几亿条记录的表,按照某个规则(比如 UserID)切成好几块,分别存放在不同的服务器上,用来分摊读写压力(负载均衡) 。
-
MongoDB: 基于文档 (Document-based) 的 NoSQL,存的实际上是 JSON 对象 。Schema-less(无模式),同一个表里的每一行数据结构可以完全不一样 。
-
HDFS (Hadoop File System): 它是分布式文件系统。主节点叫 NameNode(只存目录和块的映射信息,不存真数据),从节点叫 DataNode(存真实的硬盘块) 。为了防灾,每个数据块默认存 3 份 。
Part 11 File Organization and Indexing
这份 Part 11 讲的是文件组织和索引 (File Organization and Indexing)。
这章没有复杂的数学计算,全是纯纯的底层存储概念。你平时配过 Ubuntu 服务器、搞过自建图床,其实对文件系统和磁盘 I/O 的瓶颈肯定有感觉。数据库最怕的就是频繁读写磁盘(I/O 极慢),所以这章所有的设计,目的只有一个:减少磁盘 I/O 次数。
这章主要出选择题、判断题,极少数会考简答。直接看下面的干货拆解:
核心拿分点(必考概念辨析)
教授最喜欢把下面这两对概念混在一起考你:
-
稠密索引 (Dense Index) vs 稀疏索引 (Sparse Index)
- 稠密索引 (Dense Index): 数据表里有多少个不同的键值,索引表里就有多少条记录。
- 人话: 就像一本字典,每个字都给你标了页码。找得快,但索引本身非常大。
- 稀疏索引 (Sparse Index): 索引表里只有部分键值的记录。
- 人话: 字典侧面的 "A, B, C, D" 标签。它只告诉你 A 开头的在第 10 页,B 开头的在 50 页。
- 🚨 必考前提: 想用稀疏索引,你的物理数据文件必须是按顺序排好的 (Sequentially ordered) 。
- 查询算法: 比如你要找 45,索引里只有 10, 30, 50。你要先找 $\le 45$ 的最大值,也就是 30,然后顺着 30 的物理位置往后挨个扫描,直到找到 45 。
- 稠密索引 (Dense Index): 数据表里有多少个不同的键值,索引表里就有多少条记录。
-
主索引 (Primary Index) vs 辅助索引 (Secondary Index)
- 主索引: 决定了数据在硬盘上的物理顺序 。
- 大坑警告: 考试如果出判断题说 “Primary Index 的搜索键必须是 Primary Key”,选 False。主索引只是决定物理排列顺序,不一定要用主键 。
- 辅助索引: 也就是你平时建的普通 Index。数据的物理顺序和辅助索引的顺序完全没关系 。
- 必考推导: 因为物理顺序是乱的,所以辅助索引绝对不能是稀疏索引,它必须是稠密索引。不然你顺着物理地址往下扫,根本不知道下一个数据是什么鬼 。
- 主索引: 决定了数据在硬盘上的物理顺序 。
选择/填空防坑指南
这些概念过个眼熟,看到选项能立刻反应过来就行:
-
记录删除的三种搞法 (Deletion of Fixed-Length Records) 假设文件里删了一条记录,空出了一个洞,怎么处理?
- 方法 A (Shift): 把后面的记录全往前挪一格。(极度脑残,I/O 爆炸,千万别选)。
- 方法 B (Move last): 把文件最后一条记录拔过来填坑。(快是快,但把原本排好的顺序全打乱了)。
- 方法 C (Free List / Pointer chain): 最优解。底层维护一个空闲链表,删了就不管它,打个标记,下次有新数据直接塞进这个坑里 。
-
文件的三种组织形式 (Organization of Records)
- Heap (堆): 没任何顺序,哪里有空位塞哪里 。
- Sequential (顺序): 按某个 Search-key 乖乖排好 。
- Multitable Clustering (多表聚簇): 重点!为了加速 JOIN 操作,把几个有关联的不同表的记录,物理上挨着存放在同一个 Block 里 。比如把
计算机系和计算机系的所有老师存在同一块硬盘扇区,一次 I/O 就能全读出来 。
-
多级索引 (Multilevel Index / ISAM)
- 当你的数据量极大,连索引文件本身都塞不进内存 (RAM) 的时候怎么办?
- 解法: 给索引再建一个索引(Outer index 查 Inner index,Inner index 查物理数据)。其实这就是下一章要考的大 Boss —— B+ 树的祖先形态 。
Part 12 B-Trees
教授这章 PPT 挂着 B-Tree 的羊头,卖的其实是 B+ Tree 的狗肉。在数据库(比如 MySQL 的 InnoDB 引擎)底层,几乎全是用 B+ Tree 来做索引的。
核心拿分点 1:B+ 树“节点容量”计算公式(必考大题!)
这是重中之重。假设题目给你一棵阶数为 $n$ (Order of the tree) 的 B+ 树,你必须能肌肉记忆般写出以下参数:
-
阶数 $n$ 的本质: 阶数 $n$ 代表一个节点最多能有多少个子节点 (Children) 。注意:子节点数永远比键值数 (Keys/Values) 多 1 。
-
内部节点 (Internal Nodes - 非叶子非根):
- 最多: $n$ 个子节点,含有 $n-1$ 个键值 。
- 最少: 必须至少半满!$\lceil n/2 \rceil$ 个子节点 ,含有 $\lceil n/2 \rceil - 1$ 个键值 。(注:$\lceil \rceil$ 是向上取整,比如 $\lceil 2.5 \rceil = 3$)。
-
叶子节点 (Leaf Nodes):
- 最多: $n-1$ 个键值 。
- 最少: PPT 里针对叶子节点给了一个特殊补丁,为了保证至少半满,偶数阶的叶子节点最少键值数修改为 $\lceil n/2 \rceil$ 。但通常计算题按 $\lceil n/2 \rceil - 1$ 算基本分都在。
-
根节点 (Root Node):
- 如果树不止一层,根节点最少有 2 个子节点(1 个键值)。
核心拿分点 2:树的高度推导 (Max Height)
在处理海量数据时,树的高度 $h$ 决定了磁盘 I/O 的次数。
-
极限高度公式: 假设文件里总共有 $K$ 个搜索键值,假设每个节点都处于“最穷”的状态(也就是每个节点只有最少数量的子节点 $m = \lceil n/2 \rceil$)。
-
那么树的最大高度 $h$ 就是:$h = \lceil \log_{\lceil n/2 \rceil}(K) \rceil$ 。
-
实战带入: PPT 第 11 页举了个例子,$n=100$,一百万条数据 ($K=1,000,000$)。最少子节点数是 $\lceil 100/2 \rceil = 50$。高度 $h \approx \log_{50}(1,000,000) \approx 3.53$,向上取整就是 4 层 。只需 4 次 I/O 就能在百万数据里找到目标!
核心拿分点 3:插入与删除的“潜规则”
如果考简答题,问你插入和删除的流程,记住这几句大白话:
-
插入 (Insertion) -> 满了就“分裂” (Split):
-
找到该去哪个叶子节点,如果节点里键值数量还没达到 $n-1$,直接塞进去 。
-
如果塞满了(变成 $n$ 个了),直接劈成两半 (Split) 。前 $n/2$ 个留在老节点,后面的去新节点 。然后把新节点里的最小值复制/提拔 (Promote) 到父节点里当向导 。
-
-
删除 (Deletion) -> 穷了就“借”或“合并” (Borrow / Merge):
-
删掉一个值后,如果节点里的键值数量少于最低低保线(Under-full),怎么办?
-
先找亲戚借 (Redistribute pointers): 看看左边或右边的亲兄弟节点是不是富裕(比低保线多)。如果富裕,就匀一个过来,同时修改父节点里的向导值 。
-
亲戚也穷,只能一家人搭伙过日子 (Merge): 如果兄弟节点也刚好在低保线上,借不出来,那就直接把两个节点合并 (Merge) 成一个节点,同时把父节点里对应的向导值也删掉 。
-
概念防坑指南(选择题考点)
- B-Tree 和 B+-Tree 的唯一区别:
- B-Tree: 任何节点(包括中间的内部节点)都存着真实的数据记录的指针 。
- B+-Tree: 内部节点只存搜索键(当路标),所有的真实数据指针全部集中在最底层的叶子节点 。而且最底层的叶子节点之间有一个链表指针
$P_n$连在一起,方便做范围查询(Sequential processing)。
- 平均存储利用率 (Average Storage Utilization):
- 不用去推导那个微积分公式,直接背结论:标准的 B-Tree 平均空间利用率是 69.3% 。而有一种变体叫 $B^*$-Tree,它要求节点最少要 2/3 满,它的利用率是 81% 。
明早考卷上一旦出现 B-Tree,先把 $n$ 圈出来,然后立刻在草稿纸上写下 $n-1$ (最大键值数) 和 $\lceil n/2 \rceil$ (最小子节点数)。
Part 13 Hashing and RAID
这份 Part 13 讲的是 Hashing (哈希) 和 RAID (磁盘阵列)。
这里面的东西非常偏向底层的存储系统。教授之前透题的时候,明确提到了 Hashing and RAID 是随缘区,不一定考大题,但可能会在选择或填空里出现。我们用最快的时间把它过一遍。
核心概念与防坑指南(应对选择/判断题)
1. Hashing (哈希) 的基础概念
- Bucket (桶): 哈希表里存放数据的基本单元,通常对应一个磁盘块 (Disk block)。
- Hash Function (哈希函数) $h(K)$: 把搜索键 (Search-key) 变成一个桶地址 (Bucket address)。
- Ideal Hash Function (理想哈希函数): 是均匀 (uniform) 且 随机 (random) 的。即每个桶分配到的记录数差不多,不受实际数据分布规律的影响。
- Collision (哈希冲突/碰撞): 不同的搜索键,经过哈希函数计算后,落到了同一个桶里。
2. 静态哈希 (Static Hashing) 与溢出处理 静态哈希的桶数量是固定的。如果桶满了(Overflow),怎么处理?
- Open Addressing (开放寻址): 这个桶满了,就去旁边找个空位塞进去。(数据库里很少用,因为删数据太麻烦)。
- Overflow Chaining (溢出链/链地址法): 核心考点! 这个桶满了,就再拉出来一个额外的物理块(Overflow bucket),用链表指针连起来。所有冲突的记录都挂在这个链表上。
3. 动态哈希 (Dynamic/Extendible Hashing) 解决静态哈希桶不够用的终极方案:让桶的数量可以动态增加。
- Extendible Hashing (可扩展哈希):
- Global Depth (全局深度 $d$): 决定了目录 (Directory) 有多大(一共 $2^d$ 个槽)。我们只看哈希值的前 $d$ 位来找目录槽。
- Local Depth (局部深度 $d^{\prime}$): 存在每个具体的物理桶上的标记。表示这个桶里的数据,是根据哈希值的前 $d^{\prime}$ 位分发过来的。
- 分裂规则: 当一个桶满了需要分裂时,如果 $d^{\prime} < d$,只需增加 $d^{\prime}$ 并重排数据,目录不变。如果 $d^{\prime} == d$,不仅桶要分裂,全局目录也要翻倍($d$ 变成 $d+1$)。
4. RAID (磁盘阵列) 的级别 这是纯背诵题,记住每种 RAID 的特点和优缺点:
-
RAID 0 (Striping 条带化):
- 把数据打碎了交叉存在多个盘上。
- 特点: 读写极快(可以并行),空间利用率 100%。
- 致命弱点: 毫无冗余 (Non-redundant)。坏一块盘,所有数据全毁。适合丢了也无所谓的临时缓存。
-
RAID 1 (Mirroring 镜像):
- 两块盘存一模一样的数据。
- 特点: 最安全,恢复最快。
- 致命弱点: 贵。空间利用率只有 50%(两块 1TB 的盘加起来只能存 1TB)。
-
RAID 4 vs RAID 5 (奇偶校验分布):
- RAID 4: 有一块专门的盘用来存校验码 (Parity)。缺点是每次写任何数据,都要去改这块校验盘,这块盘会变成性能瓶颈。
- RAID 5: 工业界最常用。 把校验码 (Parity blocks) 均匀地打散 (Distributed) 存在所有盘上。
- 特点: 允许坏任意一块盘。空间利用率是 $(N-1)/N$。解决了 RAID 4 的瓶颈。
-
RAID 6: 类似 RAID 5,但是用了双重校验(P+Q),允许同时坏两块盘。
总结一下:这章不难,重点区分静态哈希的 Chaining 怎么画,动态哈希的 $d$ 和 $d^{\prime}$ 的含义,以及 RAID 0 / 1 / 5 这三个明星级别的特性。
Part 14 Transactions
这份 Part 14 是关于 事务 (Transactions),这也是期末考试的重灾区。它和接下来两章(并发控制、日志恢复)是一脉相承的。
你作为开发人员,平时写 SQL 肯定加过 BEGIN TRANSACTION 和 COMMIT。这章的核心就是在理论上解释为什么我们需要这些机制,以及多个并发事务交替执行时,怎么判断这会不会导致数据“脏乱差”。
以下是这章的必背考点和拿分逻辑:
核心拿分点 1:ACID 特性(必考选择 / 简答默写)
教授几乎每次都会考,直接默写这四个英文单词和核心含义 :
- A (Atomicity 原子性): 一个事务(例如转账)里面的所有操作,要么全部成功,要么全部失败,绝不能出现扣了钱但没加钱的中间状态。
- C (Consistency 一致性): 事务执行前后,数据库必须符合逻辑(比如转账前后,两个人的总余额不能变)。
- I (Isolation 隔离性): 多个并发事务看起来就像是串行(排队一个一个)执行的。一个事务没提交之前,它修改的中间结果对别人是不可见的。
- D (Durability 持久性): 一旦你点击了
COMMIT(提交),数据就永远写死在硬盘里了。哪怕下一秒机房断电被陨石砸了,重启后数据也不能丢。
核心拿分点 2:冲突可串行化 (Conflict Serializability)(必考判断/推导)
这是判断一个并发时间表 (Schedule) 对不对的核心标准。在同一时间段内并发执行两个事务,如果可以通过交换“没有冲突”的指令,把它还原成串行排队的顺序,那它就是合法的。
什么是冲突 (Conflicting Instructions)? 当事务 $T_1$ 和 $T_2$ 同时去碰同一个变量 $Q$ 时,只要有一个人在做写操作 (Write),就叫冲突 !
Read(Q)和Read(Q):不冲突(大家只看不改,随便换顺序)。Read(Q)和Write(Q):冲突(你读旧值还是读新值,顺序极其重要)。Write(Q)和Write(Q):冲突(谁最后写,谁的值就留下来)。
怎么做大题: 如果在卷子上看到两个事务的时间表,让你证明是不是 Conflict Serializable:
-
只要它们操作的不是同一个变量(比如 $T_1$ 读 A,$T_2$ 写 B),你可以随便上下交换它们的位置。
-
只要你能通过交换,把 $T_1$ 所有的指令全挪到 $T_2$ 的上面(或者反过来),那就证明成功了 。
-
反面教材(PPT 第 16 页的那个叉叉图): 如果 $T_1$ 读了 $Q$,$T_2$ 紧接着写了 $Q$(形成读写冲突,顺序锁死 $T_1 \rightarrow T_2$),然后 $T_1$ 后来又写了 $Q$(形成写写冲突,顺序锁死 $T_2 \rightarrow T_1$)。出现了互相锁死的死循环,这就叫 Not conflict serializable 。
核心概念与防坑指南(应对选择题)
-
级联回滚 (Cascading Rollbacks) 和 脏读 (Dirty Read)
- 假设你($T_1$)改了数据,还没提交。我($T_2$)跑过来读了你改的数据(这叫脏读 Dirty Read)。
- 结果你突然反悔了,报错回滚(Abort)了。
- 因为我读了你的假数据,系统为了保证一致性,被迫把我也一起回滚了。这叫级联回滚。
-
如何防止级联回滚?(Cascadeless Schedules)
- 规则很简单:在我($T_2$)读你的数据之前,**你($T_1$)必须已经执行了
COMMIT**。不允许读未提交的数据 。
- 规则很简单:在我($T_2$)读你的数据之前,**你($T_1$)必须已经执行了
-
SQL 的四种隔离级别 (Isolation Levels) 直接看 PPT 最后一页那个表格,背下来。级别越来越高,性能越来越差:
- READ UNCOMMITTED(读未提交): 最拉胯,什么问题都能出(允许脏读、不可重复读、幻读)。
- READ COMMITTED(读已提交): 解决了脏读,但解决不了同一事务里两次读数据不一样的问题。
- REPEATABLE READ(可重复读): 解决了脏读和不可重复读。
- SERIALIZABLE(可串行化): 最高级别,啥问题都没有,相当于排队执行,性能最慢。
Part 15 Concurrency Control and Recovery
这两道大题在真题里加起来接近 20 分,而且套路极其固定,纯送分。我们直接把这章的黑话翻译成你的考场拿分公式。
核心拿分点 1:Undo 与 Redo 的终极判据(必考大题!)
真题里一定会给你一个带有 <T0 start>, <T0 commit>, <checkpoint L> 和 system failure (系统崩溃) 的时间轴或日志列表。你要做的是判断每个事务该 Undo (撤销) 还是 Redo (重做)。
大白话解题口诀: 系统崩溃后,我们往回看日志:
- Redo (重做) 的条件: 只要一个事务既有
<T start>,**又有<T commit>或<T abort>**,说明它在崩溃前已经走完了流程。为了防止数据没写进硬盘,我们要把它放进 Redo 名单 。 - Undo (撤销) 的条件: 只要一个事务有
<T start>,但是**找不到<T commit>**,说明它干到一半系统挂了。这种半吊子数据必须被撤销,放入 Undo 名单 。
⚠️ 加入 Checkpoint (检查点) 后的高阶玩法: Checkpoint 就像是游戏里的存档点。
-
如果一个事务在
<checkpoint L>之前就已经 commit 了,它的数据肯定已经安全落盘了。考试时直接无视它,既不 Undo 也不 Redo! -
只有在 Checkpoint 列表
L里的(也就是存档时还在运行的),或者在 Checkpoint 之后才 start 的事务,才需要用上面那个 “Undo/Redo” 的口诀去判断 。
核心拿分点 2:两阶段锁协议 (Two-Phase Locking / 2PL)
这也是简答题常客。你写过多线程和协程,对锁肯定不陌生。教授如果问你 2PL 是什么,直接答这两条铁律:
-
阶段一 (Growing Phase - 加锁阶段): 事务只能不断获取锁,绝对不能释放任何锁 。
-
阶段二 (Shrinking Phase - 解锁阶段): 一旦事务释放了第一个锁,就进入了第二阶段。在这个阶段,它只能释放锁,绝对不能再请求任何新锁 。
-
必背结论: 只要遵守 2PL,就绝对能保证冲突可串行化 (Serializability) 。但是,2PL 不能防止死锁 (Deadlock) !
概念防坑指南(应对选择题 / 判断题)
遇到选择题,秒选以下几个关键字:
1. S 锁与 X 锁的兼容性
-
S 锁 (Shared/读锁): 兼容 S 锁。大家都可以一起读 。
-
X 锁 (Exclusive/写锁): 霸道总裁,谁都不兼容。只要有人拿了 X 锁,其他人既不能读也不能写 。
2. 死锁 (Deadlock) vs 饥饿 (Starvation)
-
死锁: $T_1$ 拿着 A 等 B,$T_2$ 拿着 B 等 A,两个人互相等,彻底卡死 。
-
饥饿: 一个老实人想拿写锁,但是后面疯狂来了一群人拿读锁(读锁不互斥所以一直放行),导致老实人无限期等待。这不是死锁,系统还在运行,只是他被饿死了 。
3. WAL 原则 (Write-Ahead Logging)
- 这个原则是数据库不丢数据的命根子:在把内存里改好的真实数据块写进硬盘之前,必须先把相关的 Log (日志) 写进硬盘 。先记账,后花钱。
4. 影子分页 (Shadow Paging)
-
教授如果考这个,就找一个词:NO-UNDO/REDO。
-
它的原理是维护两张目录表(当前目录和影子目录)。崩溃了怎么办?直接把当前目录扔掉,一秒切换回影子目录,什么 Undo/Redo 都不需要做 。
Part 16 OLAP and Data Warehouse
这份 Part 16 讲的是 OLAP (在线分析处理) 和 Data Warehouse (数据仓库)。
这章在两份 22 年的真题里都考了简答题和计算题(占了将近 15 分)。这章没有任何复杂的底层算法,全是概念和简单的排列组合。我们直接把它扒光:
核心拿分点 1:ROLLUP 和 CUBE 的算组公式(必考大题!)
真题(Spring 2022 Q5)里直接考了:给你几个维度的属性,问你 GROUP BY ROLLUP 和 GROUP BY CUBE 会输出多少行(tuples)?这里有一个秒杀公式,千万别在考场上傻傻地穷举!
假设有三个维度 A, B, C,它们各自有 $a, b, c$ 种不同的取值(比如 A 是衣服款式有 2 种,B 是尺码有 3 种,C 是颜色有 2 种)。
-
CUBE (A, B, C)的秒杀公式:-
CUBE 会把所有的组合全部列出来。每一列除了它本身的取值,还会多出一个
ALL(也就是不管这个维度,算总和)。 -
公式: 输出行数 $= (a+1) \times (b+1) \times (c+1)$
-
实战带入(22年春季真题): $a=2, b=3, c=2$。直接算 $(2+1) \times (3+1) \times (2+1) = 3 \times 4 \times 3 = \mathbf{36}$ 行。直接拿满分!
-
-
ROLLUP (A, B, C)的计算逻辑:-
ROLLUP 是有顺序的“向上汇总”(只从右边开始一个个丢掉属性)。它只会生成 4 种分组:
(A,B,C),(A,B),(A),()。 -
公式: $(a \times b \times c) + (a \times b) + a + 1$
-
实战带入: $(2 \times 3 \times 2) + (2 \times 3) + 2 + 1 = 12 + 6 + 2 + 1 = \mathbf{21}$ 行。再次满分!
-
核心拿分点 2:星型模式 (Star Schema) 与 雪花模式 (Snowflake)
必考简答题,问你什么是 Star Schema,为什么 Snowflake 不好。
-
Star Schema (星型模式):
-
中心是事实表 (Fact Table): 极其庞大,高度规范化,存的都是能进行数学计算的“事实”(比如销量、销售额),以及一堆外键。
-
四周是维度表 (Dimension Tables): 比较小,故意不进行规范化 (Denormalized)。存的是文字描述(比如具体的商品名、颜色、生产厂家信息全塞在一张表里)。
-
-
为什么 Snowflake Schema (雪花模式) 被教授嫌弃 (Undesirable)?
- 雪花模式把“维度表”也规范化了(比如把生产厂家单独又拆成一张表),导致表变得非常多。在做数据分析(浏览/查询)时,需要做极其海量的 JOIN 操作,性能直接爆炸。所以在数据仓库里,为了查询快,我们宁愿维度表有数据冗余(不满足范式)。
概念防坑指南(选择题 / 简答默写)
1. Data Warehouse (数据仓库) 的四大金刚特征: 如果考默写,记住这四个词:
-
Subject-oriented (面向主题): 不按业务流程来,而是按大主题(比如“客户”、“销量”)组织。
-
Integrated (集成的): 把各个不同系统、不同格式的数据洗干净整合在一起。
-
Non-volatile (非易失的 / 绝不修改): 数据一旦装进去就绝对不会 Update 或 Delete,只有批量导入和查询。(和我们平时的关系型数据库完全相反)。
-
Time-variant (时间维度的): 存的是历史快照,带时间戳,用来做趋势分析。
2. 数据魔方 (Data Cube) 的四个切切切操作: 教授喜欢考这些名词的区别:* Rollup (上卷): 视角变粗。比如从“按天统计”变成“按月统计”。
-
Drill-down (下钻): 视角变细。比如从“按国家统计”深入到“按省份统计”。
-
Slicing (切片): 锁死一个维度。比如只看“2026年”的数据。
-
Dicing (切块): 锁死多个维度。比如看“2026年”且“在中国”的数据。
这章就是纯纯的送分题,记住 CUBE 的 $(a+1)(b+1)(c+1)$ 乘法公式,明天如果有这道题,别人苦哈哈地穷举,你 5 秒钟直接出答案。
Part 17 Data Mining
这绝对不是随缘区,这是必拿的硬核送分题。这章不考写代码,全是纯数学的“杂质计算”(Impurity)。
既然这是你发的三个 PPT 里的第一个(Part 17),我们立刻把它最核心的拿分点生吞活剥。
核心拿分点 1:决策树的 Entropy(信息熵)计算(必考大题)
决策树在分类的时候,终极目标就是把人群分得越纯越好。什么是“纯”?比如一个节点里全是男生(纯),或者全是女生(纯)。最怕的就是男女各占一半(杂乱)。Entropy(熵)就是用来衡量“杂乱程度”的指标。
-
越纯,Entropy 越接近 0。(最好)
-
越杂乱(各占一半),Entropy 越接近 1。(最烂/Least desirable)
💥 必背公式: 假设一个节点有两类人(C1 和 C2),概率分别是 $p_1$ 和 $p_2$。 $Entropy = - (p_1 \times \log_2(p_1) + p_2 \times \log_2(p_2))$ (注意:遇到 $p=0$ 的情况,规定 $0 \times \log_2(0) = 0$)
真题实战破解(2022年 Q8/Q7): 题目给了三个节点:
C1: 0, C2: 6$\rightarrow$ 总共6人,$p_1 = 0, p_2 = 1$ $\rightarrow$ $Entropy = 0$(最纯)C1: 1, C2: 5$\rightarrow$ 总共6人,$p_1 = 1/6, p_2 = 5/6$ $\rightarrow$ $Entropy \approx 0.65$C1: 2, C2: 4$\rightarrow$ 总共6人,$p_1 = 2/6, p_2 = 4/6$ $\rightarrow$ $Entropy \approx 0.918$(最杂乱)
答题标准话术: The node (C1: 2, C2: 4) is the least desirable. Because its entropy is the highest among the three, meaning it has the highest impurity (most mixed classes). Decision trees aim to create nodes with the lowest possible entropy.
核心拿分点 2:Gini Index(基尼系数)的最大值证明(必定原题重现)
连续两年的卷子最后一题,全在让你用数学证明:“证明当所有类别人数均匀分布时,基尼系数取得最大值,并求出这个最大值。” 遇到这题,直接把下面这套数学推导抄上去,10 分满分到手!
💥 Gini 核心公式: $Gini = 1 - \sum_{i=1}^{c} p_i^2$ (其中 $c$ 是类别总数,$\sum p_i = 1$)
背诵版证明过程(抄到答题纸上):
-
We want to maximize the Gini Index: $Gini = 1 - \sum_{i=1}^{c} p_i^2$.
-
This is equivalent to minimizing the sum of squares: $\sum_{i=1}^{c} p_i^2$, subject to the constraint $\sum_{i=1}^{c} p_i = 1$.
-
By the Cauchy-Schwarz inequality (柯西不等式) or using Lagrange multipliers: $(\sum_{i=1}^{c} p_i^2) \times (\sum_{i=1}^{c} 1^2) \ge (\sum_{i=1}^{c} p_i \times 1)^2$
-
Since $\sum 1^2 = c$ and $\sum p_i = 1$, we get: $(\sum_{i=1}^{c} p_i^2) \times c \ge 1^2 \Rightarrow \sum_{i=1}^{c} p_i^2 \ge \frac{1}{c}$
-
The minimum value of $\sum p_i^2$ is $\frac{1}{c}$, which occurs when all $p_i$ are equal (i.e., $p_1 = p_2 = ... = p_c = \frac{1}{c}$). This corresponds to an equal distribution among all classes.
-
Therefore, the maximum Gini Index is: $1 - \frac{1}{c} = \frac{c-1}{c}$. (注:如果题目明确说是 2 个类别,即 c=2,那最大值就是 $1 - 1/2 = 0.5$)
概念防坑指南(K-Means 聚类)
PPT 里还提到了 K-Means 计算(给几个坐标点让你算距离),这也是高频考点。
-
算法口诀: 找两个圆心 $\rightarrow$ 算出所有点到这两个圆心的距离 $\rightarrow$ 谁近就归属谁 $\rightarrow$ 重新把这群人的坐标求平均,得出新的圆心 $\rightarrow$ 重复。
-
考场上遇到这种题,记得带上你的科学计算器算欧氏距离(勾股定理 $\sqrt{(x_1-x_2)^2 + (y_1-y_2)^2}$)。
Part 18 Parallel and Distributed Databases
只要记住下面这几个核心的“对比概念”,这章的分数你就全拿下了:
核心拿分点 1:Speedup (加速比) vs Scaleup (扩展比)
这是极其经典的必考判断题 / 选择题,不要搞混了:
-
Speedup (加速比): 任务大小不变,我给你加机器(比如把服务器从 1 台加到 10 台)。
- 理想结果(Linear Speedup): 时间应该缩短到原来的 1/10。
-
Scaleup (扩展比): 任务变大了,同时机器也变多了(比如数据量涨了 10 倍,我也给你加 10 倍的服务器)。
- 理想结果(Linear Scaleup): 花费的时间应该和原来一模一样(保持为 1)。
核心拿分点 2:三种并行架构 (Parallel Architectures)
如果考简答题让你对比架构,用大白话这么解释:
-
Shared Memory (共享内存): 所有的 CPU 共同读写同一块超大内存。
- 缺点: 极容易撞车(瓶颈在于内存总线),最多只能支持几十个 CPU。
-
Shared Disk (共享磁盘): 每个 CPU 有自己的独立内存,但大家连着同一块大硬盘。
- 优点: 一台机器挂了,别的机器还能接着读硬盘。
- 缺点: 网络传输数据成瓶颈。
-
Shared Nothing (无共享): 最高频考点! 每台机器都是完全独立的(自己的 CPU + 自己的内存 + 自己的硬盘),机器之间只通过网线发消息。
- 优点: 扩展性无敌 (Massively scalable)。你平时玩的集群、Hadoop、大数据架构,全都是基于 Shared Nothing 搞的。
核心拿分点 3:数据分片 (Data Fragmentation)
分布式系统里,一张几亿条记录的表怎么拆分到不同机器上?教授喜欢考这两种切法的区别:
- 水平分片 (Horizontal Fragmentation): 按行切。
- 例子: 按照
部门切。把“计算机系”的所有老师(完整的行数据)存在机器 A,“物理系”的存机器 B。
- 例子: 按照
- 垂直分片 (Vertical Fragmentation): 按列切。
- 例子: 把
身份证, 姓名, 地址这些不敏感的列存在机器 A,把身份证, 薪水, 绩效这些敏感的列存在机器 B。 - ⚠️ 必考大坑: 垂直分片的时候,每一片都必须包含主键(Primary Key)! 不然你把两片数据拉回来 JOIN 的时候,根本不知道谁是谁的薪水。
- 例子: 把
核心拿分点 4:两阶段提交协议 (Two-Phase Commit / 2PC)
前面事务那章讲了单机怎么保证原子性 (Atomicity)。那如果是分布式系统(比如从北京的银行往香港的银行转账),怎么保证两边同时成功或同时失败?
- 第一阶段 (准备阶段): 老大 (Coordinator) 发微信群发问所有人:“你们都把数据写进日志、准备好提交了吗 (Ready)?”
- 第二阶段 (决断阶段):
- 只要所有人都回复“Ready”,老大就下令:“全体 Commit!”
- 只要有哪怕一个人回复“不行”或者干脆掉线没回复,老大直接下令:“全体 Abort (回滚)!”
🍻 终极通关总结
兄弟,到这里所有的 PPT 已经全部过完了。你现在的武器库里有:
- B+ Tree 参数与高度计算公式(必考 15 分大题,注意阶数 $n$ 的含义)。
- 4NF 与 MVD 的无损分解(拆表公式)。
- Undo/Redo 的 Log 分析(看有没有 commit)。
- 冲突可串行化与 2PL 锁。
- CUBE 和 ROLLUP 的行列计算公式。
- 决策树 Entropy 与 Gini Index 证明。
Final Exam
判断题,单选题,填空题,大题
-
multivalue/function dependency
-
lossless decomposition (NF)
-
4nf/bcnf
-
file processing & indexing
-
b tree
-
cap theorem(no sql)
-
H base data model and relational data model comparison
-
recovery track(undo...)